在写后台大屏数据接口碰见了一个问题,面对Map<String, Map<String, Object>>这种类型,我希望获取内层 Map下指定key的value累加,也就是内存Map中大部分都有几个相同的Key,比如合同金额,收款金额,我想通过便捷的方式获取统计
换一种说法贴合业务理解,这个结构是外层Map key表示流程ID也就是唯一标识,value也就是内层Map代表得是这个流程下所有得表单值,通过key,value存储,这样说应该好理解了吧?
如何累加通过key的value?
通过foreach循环 我第一个想到的方法是
// 模拟数据:Map<流程实例ID, Map<变量名, 变量值>> Map<String, Map<String, Object>> processValues = new HashMap<>(); // 流程实例1 Map<String, Object> variables1 = new HashMap<>(); variables1.put("amount", 1000); variables1.put("quantity", 5); variables1.put("approver", "张三"); variables1.put("status", "已完成"); processValues.put("proc_001", variables1); // 流程实例2 Map<String, Object> variables2 = new HashMap<>(); variables2.put("amount", 2500); variables2.put("quantity", 8); variables2.put("approver", "李四"); variables2.put("status", "进行中"); processValues.put("proc_002", variables2); // 流程实例3 Map<String, Object> variables3 = new HashMap<>(); variables3.put("amount", 1500); variables3.put("quantity", 3); variables3.put("approver", "王五"); variables3.put("status", "已完成"); processValues.put("proc_003", variables3);第一种实现 也是最简单的 Map<String, Object> sumMap = new HashMap<>(); // 通过遍历累加 for (Map<String, Object> value : processValues.values()) { int amount = (Integer) sumMap.get("amount"); int receivedAmount = (Integer) sumMap.get("quantity"); sumMap.put("amount", amount + (Integer) value.get("amount")); sumMap.put("quantity", receivedAmount + (Integer) value.get("quantity")); }通过stream流的reduce实现
项目中很少用到,但是这次有时间我就研究一下,有时候改变编程习惯,面对困难也有选择的余地.
reduce的定义
reduce 是 Stream API 中的一个归约操作,用于将流中的多个元素反复组合,最终得到一个单一的结果
这里说的最终单一 并不是说结果只是一个值,也可以是对象,对象里面也可以有多个值,别理解错了。比如我们上面这个Map要的效果并不是把 map 里面的多个key合成一个,而是不同key分别累计,最终达到不同key的value值单一stream流中reduce的三种方法

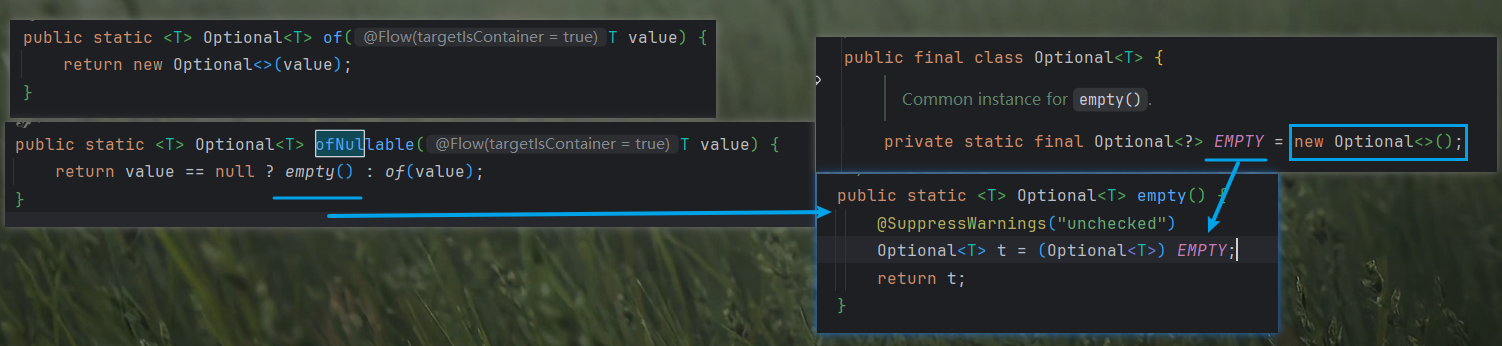
1. Optional<T> reduce(BinaryOperator<T> accumulator); 先讲第一个方法, 这个方法只需要一个参数,并且返回值是Optional类型 a. Optional类型是什么? 一个容器类,也可以理解为一个包装类,通过方法把对象|值 存入里面,他提供了一系列链式调用来处理,比如常用的 判断一个对象是否为空以及里面某个值是否为?来进行不同的逻辑 // 传统方式 - 需要手动判空 String name = null; if (user != null) { name = user.getName(); } // Optional 方式 - 容器封装了判空逻辑 String name = Optional.ofNullable(user) .map(User::getName) .orElse("Unknown"); > 通过这段源码可以理解我们写一些util类,可以通过返回optional<T> 来简化调用方的判断处理逻辑🤔 下图说明了of 和 ofNullable的区别,相对于调用Nullable健壮性更好,在为null的情况下,他会创建一个空的Optional对象
b. BinaryOperator的定义
一个函数式接口,从源码来看泛型<T,T,T> 传入2个相同类型的参数返回一个也是同类型的参数.
继承自BiFunction,BiFunction的泛型是 <T, U, R> 接收一个T类型 操作一个U函数 返回R类型
从BinaryOperator的官方备注可以看到,这个是对BiFunction的专业化,只针对同类型的操作. 简单理解的话 这些接口是官网 为了提供在不同情况下的 规范标准,理解是个规范就可以了,就和List,Set集合都继承自Collection是一样的
示例1:
Optional<Integer> amount = processValues.values().stream().map(o -> (Integer)o.get("amount"))
.reduce((m, i) -> {
m += i;
return m;
});
结果返回: Optional[5000]
示例2: 通过lambda表达式优化
Optional<Integer> amount = processValues.values().stream().map(o -> (Integer)o.get("amount")).reduce(Integer::sum); 2. T reduce(T identity, BinaryOperator<T> accumulator);
相比于第一个单入参方法,这个方法需要额外传入一个identity,可以理解为初始值
⬇️下面是源码的解释
T result = identity;
for (T element : this stream) {
result = accumulator.apply(result, element)
return result;
}
也就是说这个方法支持对累计初始化值可以自定义,而第一个只能通过元素1+2+N
注意这里泛型都是T,也就是他限制了调用传入的 初始值 identity| 累计函数 accumulator 都必须类型一致,最后返回值也是T
1. 2个参数的reduce备注中有一段需要注意的点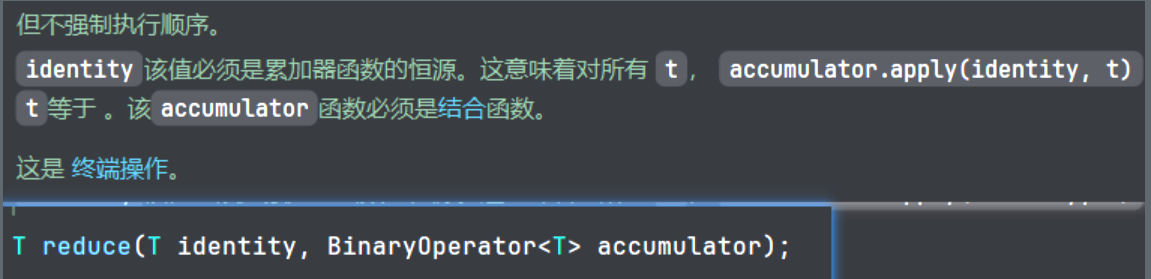
执行并不是按照顺序的,下面也提到了 ```结合函数``` 也可以理解为数学的结合律
结合律是什么?
相同运算符的表达式中,只要运算符的位置不变,运算顺序对结果没有影响
1. 加法中✔️
(1 + 2) + 3 = 1 + (2 + 3)
2. 减法中✖️
(10 - 5) - 2 ≠ 10 - (5 - 2) 这种情况
因为定义Stream流分为 stream() 和 parallelStream()[支持并行] ,不过我还没用过并行
3. <U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
这个方法 又在第二种方法的基础上扩展了一个参数
相比于2入参方法,这里有个细节就是accumulator变成了BiFunction类型,通过源码可以看到 BiFunction<T, U, R>正是之前单入参 BinaryOperator的父接口,且他的入参类型T和返回结果R是允许不同的,2个入参用的 BinaryOperator<T> extends BiFunction<T,T,T> 所以说2个参数与返回值都必须同一类型
第三个参数 combiner 表示组合函数,因为parallelStream并行流的存在,所以支持一个集合拆分多个执行,但是最后怎么合并呢? 这时候就需要通过第三个入参设置合并数据逻辑 他支持传入2个参数,也就是一次只能处理2个结果的操作,但是最终会把这些结果单一化输出
这个时候有个问题,既然是并行为什么不能一次处理多条数据组合呢?
1. 两两组合效率更高
2. BiFunction接口下 R apply(T t, U u) 也只定义了2个 而BinaryOperator有对其限制 BiFunction<T,T,T> 所以为什么 BinaryOperator 定义函数是2个一样的值
示例1:
List<String> words = Arrays.asList("Hello", " ", "World", "!", " ", "Java");
String result = words.stream()
.reduce(
"", // identity: 初始值
(partial, word) -> partial + word, // accumulator: 累加器
(r1, r2) -> r1 + r2 // combiner: 合并器
);
解释这个示例,words集合开始遍历
第一个参数设置为 "" 表示初始值不做修改 走默认拼接
第二个参数设置 从逻辑上开就是每次用初始值+words迭代的元素 即:
第一次迭代 => "" + "Hello"
第二次迭代 => "Hello" + " "
第三次迭代 => "Hello " + "!"
第三个参数 要在parallelStream下才会被调用,用stream()自定义也不会生效
模拟运行逻辑
原始数据: ["Hello", " ", "World", "!", " ", "Java"]
↓ Fork/Join 框架分割
假设分割成 3 个任务(实际取决于CPU核心数):
任务1: ["Hello", " "] → 线程A处理
任务2: ["World", "!"] → 线程B处理
任务3: [" ", "Java"] → 线程C处理
然后到这里就会把这3个任务传入到(r1, r2)
再根据-> r1 + r2 这里的逻辑进行组合
🫱 实际操作下来发现面对复杂对象还是通过Collect链式处理更好,如果是单一集合用reduce效果更好更快
总结
reduce可以对 任意类型的 集合/流 进行聚合操作
stream流默认提供了3个方法
单参数 只需要我们提供结合规则
双参数 支持自定义一个初始累计值,但是类型必须一致
三参数 用于定义并行下 最终计算值的组合输出
支持并行操作,需使用parallelStream()引用
如果不是则第三个组合参数不会生效并行执行要考虑 结合律 问题
ps: 额外知识
Optional<T> 接口 可以包装指定对象,让对象在程序中显示操作,而不是靠被动报错NPE来处理
BiFunction|BinaryOperator 通过传入2个参数返回一个值的 规则类,明白了泛型不止于一个<T>,还能通过
,逗号去定一个多个类型